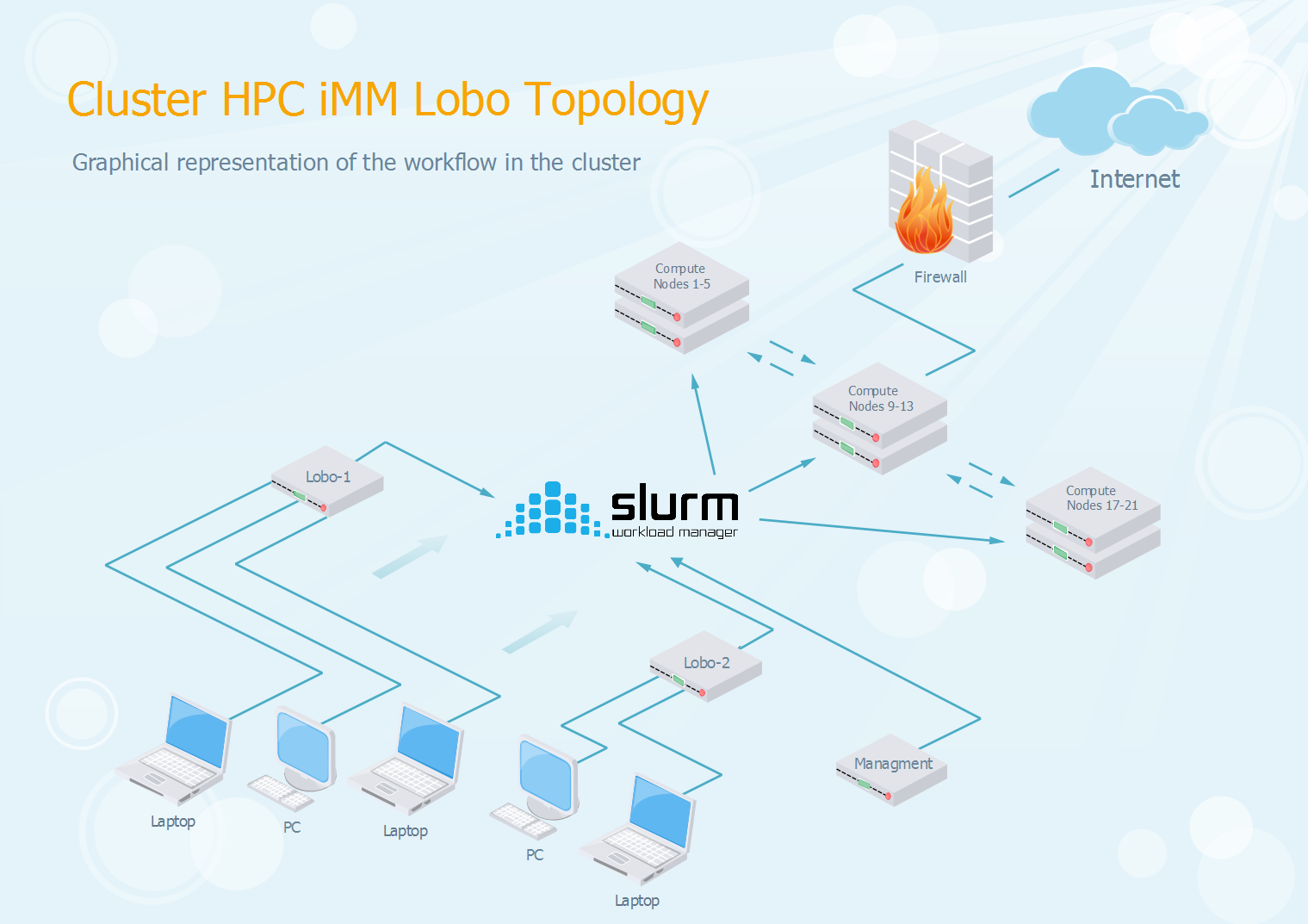
Access to iMM Lobo HPC Cluster¶
The cluster iMM Lobo can be accessed using SSH (default port 22) into the login nodes. User accounts are created on demand, so users should request access via email (imm-itsupport@medicina.ulisboa.pt) with your SSH public key attached. This cluster does not use password as an authentication method, because generally passwords are easier to exploit. If you have doubts on how to generate your personal set of keys, there are instructions in the “SSH2 Keypair” separator. From a Windows operating system, a 3rd party SSH Client must be used like Putty, and/or from OS X and Linux, a native client is supported from terminal as follows:
ssh username@lobo.imm.medicina.ulisboa.pt
External iMM account can also be created if justified, for example, external users collaborating with an iMM lab or Project, or an internship student looking to develop his thesis in the bioinformatics area.
Using Shifter at Lobo¶
Shifter is a software package that allows user-created images to run at Lobo, these images are generally Docker images, and with this system, you can obtain your desired operating system and easily install your software stacks and dependencies. If you make your image in Docker, it can also be run at any other computing center that is Docker friendly. Shifter also comes with improvements in performance, especially for shared libraries. The first step to build your own personal image is to make a docker file with your desired software and operating system. You can construct this file on your own personal computer, or at the cluster login nodes (Lobo-1/Lobo-2). When you’re building images it’s better to try to keep the image as compact as possible, since this will decrease the time to upload the image to Docker Hub and to upload it into the Shifter framework. You can keep image size down by removing software sources zip’s after you install them and by limiting images to specific target applications and what is needed to support them.
Downloading Shifter Images to Lobo¶
Shifter images can be downloaded from public docker repositories.
shifterimg -v pull docker_hub:image_name:latest
Where docker:image_name:latest is replaced with some existing and publicly available docker image (like docker:ubuntu:16.04). The output will update while the image is pulled down and converted so it can run on our systems. Once the “status” field is “READY”, the image has been downloaded and can be used. To see a list of all available images, type:
shifterimg images
In the future, pulling Shifter images from private repositories or sources other than Docker will be enabled.
Slurm Workload Manager¶
iMM Lobo cluster uses a task scheduler called SLURM (Simple Linux Utility for Resource Management) to control access to hardware resources. Since the cluster is a shared system used by multiple users, access is managed through this queue system. The scheduling and usage rules are designed together to help support the productivity goals of the cluster, including: * Throughput – handle as many jobs as possible from our users. * Utilization – don’t leave processors idling if work is available. * Responsiveness – if you submit a job that will take X hours to run, ideally it shouldn’t have to wait more than X hours to start. * Give priority to faculty who have contributed to iMM-Lobo, but support the work of community users as much as possible.
To use this system, you need to put together a batch script with the parameters you want to pass to Slurm on what type of system resources are going to be used. These “parameters” include the amount of nodes, cpus, memory and running hours necessary for your type of work.
Sample Batch Script¶
#!/bin/bash
#SBATCH --job-name= my-job-name # Job name
#SBATCH --nodes=1 # Use one node
#SBATCH --ntasks=1 # Run a single task
#SBATCH --cpus-per-task=10 # Number of CPU cores per task
#SBATCH --mem=20G # Total memory limit
#SBATCH --time=72:00:00 # Time limit hrs:min:sec
#SBATCH –-output=/home/username/my-job-name-%j.out # Output results to home folder
#SBATCH –-error=/home/username/my-job-name-%j.err # Output errors to home folder
#SBATCH --image=docker:repository/name:tag # Specify Docker image
#SBATCH --workdir=/home/username/scratch/ # Work directory environment
export GENOME=/mnt/mountpoint/lobo/*****
srun shifter program parameters $GENOME
Batch Script Parameters¶
| --job-name=<name> | |
| Specify a name for the job allocation. The specified name will appear along with the job id number when querying running jobs on the system. The default is the name of the batch script, or just “sbatch” if the script is read on sbatch’s standard input. | |
| --output=<filename pattern> | |
| Instruct Slurm to connect the batch script’s standard output directly to the file name specified in the “filename pattern”. By default both standard output and standard error are directed to the same file. For job arrays, the default file name is “slurm-%A_%a.out”, “%A” is replaced by the job ID and “%a” with the array index. For other jobs, the default file name is “slurm-%j.out”, where the “%j” is replaced by the job ID. See Filename Specifications for filename specification options. | |
| --error=<filename pattern> | |
| Instruct Slurm to connect the batch script’s standard error directly to the file name specified in the “filename pattern”. See –output . | |
| --nodes=<minnodes[-maxnodes]> | |
| Request that a minimum of minnodes nodes be allocated to this job. A maximum node count may also be specified with maxnodes. If only one number is specified, this is used as both the minimum and maximum node count. | |
| --ntasks=<number> | |
| sbatch does not launch tasks, it requests an allocation of resources and submits a batch script. This option advises the Slurm controller that job steps run within the allocation will launch a maximum of number tasks and to provide for sufficient resources. The default is one task per node, but note that the –cpus-per-task option will change this default. | |
| --cpus-per-task=<ncpus> | |
| Advise the Slurm controller that ensuing job steps will require ncpus number of processors per task. Without this option, the controller will just try to allocate one processor per task. | |
| --mail-user=<mail@example.com> | |
| Specifies the email address to which the messages are sent. | |
| --mail-type=<type> | |
| Notify user by email when certain event types occur. Valid type values are NONE, BEGIN, END, FAIL, REQUEUE, ALL (equivalent to BEGIN, END, FAIL, REQUEUE, and STAGE_OUT), STAGE_OUT (burst buffer stage out and teardown completed), TIME_LIMIT, TIME_LIMIT_90 (reached 90 percent of time limit), TIME_LIMIT_80 (reached 80 percent of time limit), TIME_LIMIT_50 (reached 50 percent of time limit) and ARRAY_TASKS (send emails for each array task). Multiple type values may be specified in a comma separated list. The user to be notified is indicated with –mail-user. Unless the ARRAY_TASKS option is specified, mail notifications on job BEGIN, END and FAIL apply to a job array as a whole rather than generating individual email messages for each task in the job array. | |
| --time=<time-format> | |
| Specifies the amount of time (in minutes) that your program will run before being automatically killed. Acceptable time formats include “minutes”, “minutes:seconds”, “hours:minutes:seconds”, “days-hours”, “days-hours:minutes” and “days-hours:minutes:seconds”. | |
| --mem=<memory-unit> | |
| Specify the real memory required per node in megabytes. Different units can be specified using the suffix [KMGT]. | |
Remember to always test your batch scripts first on a test environment to look for any unwanted behavior, and only then apply them on the cluster. Any job that is disruptive to other users work will be terminated, and the job owner notified by USI.
Filename Specifications¶
The filename pattern may contain one or more replacement symbols, which are a percent sign “%” followed by a letter (e.g. %j).
Supported replacement symbols are:
- \\
- Do not process any of the replacement symbols
- %%
- The character “%”
- %A
- Job array’s master job allocation number
- %a
- Job array ID (index) number
- %j
- Job allocation number
- %N
- Node name. Only one file is created, so %N will be replaced by the name of the first node in the job, which is the one that runs the script
- %u
- User name
Batch Script Environment Variables¶
| Variable | Description |
|---|---|
| SLURM_JOB_ID | Job ID number given to this job. |
| SLURM_JOB_NAME | Name of this job. |
| SLURM_JOB_NODELIST | List of nodes allocated to the job. |
| SLURM_CPUS_PER_TASK | Number of cores requested (per node) |
Slurm Usage Examples¶
Job Submission¶
sbatch my_job.sbatch
Queue status¶
squeue
Node status¶
sinfo
Detailed Job status¶
scontrol show job JOB_ID
Cancel Job¶
scancel JOB_ID
Re-queue Job (job needs to be running)¶
scontrol requeue JOB_ID
or
scontrol requeue JOB_ID1,JOB_ID2,...,JOB_IDN
All other Slurm commands should work as in other computational clusters. Check the user documentation for details.
SSH2 Keypair¶
This page provides instructions on how to generate a SSH2 Keypair.
Linux¶
In a running terminal window:
$ ssh-keygen
Your private key should be located in ~/.ssh/id_rsa or ~/.ssh/id_dsa Your public key should be located in ~/.ssh/id_rsa.pub or ~/.ssh/id_dsa.pub
Mac OS X¶
In a running terminal window:
$ ssh-keygen
Your private key should be located in ~/.ssh/id_rsa or ~/.ssh/id_dsa Your public key should be located in ~/.ssh/id_rsa.pub or ~/.ssh/id_dsa.pub
Windows¶
Natively Windows does not provide a tool to generate such a pair.
However you can use external tools, such as PuTTYgen which can be found here.
Using PuTTYgen¶
Generating your key pair¶
Before generating a key pair using PuTTYgen, you need to select which type of key you need.
- Select SSH2 RSA
Press the Generate button and PuTTYgen will begin the process of actually generating the key.
The Key passphrase and Confirm passphrase boxes allow you to choose a passphrase for your key. The passphrase will be used to encrypt the key on disk, so you will not be able to use the key without first entering the passphrase.
If you leave the passphrase fields blank, the key will be saved unencrypted. You should not do this without a good reason, if you do, your private key file on disk will be all an attacker needs to gain access to any machine configured to accept that key.
Once you have generated a key, set a comment field and set a passphrase, you are ready to save your private key to disk.
Saving your private key to disk¶
Press the Save private key button. PuTTYgen will put up a dialog box asking you where to save the file. Select a directory, type in a file name, and press Save.
Saving your public key to disk¶
To save your public key in the SSH-2 standard format, press the Save public key button in PuTTYgen. PuTTYgen will put up a dialog box asking you where to save the file. Select a directory, type in a file name, and press Save.
Converting Keys from PuTTY to OpenSSH format¶
If you generate your key pair on Windows before following this guide, it is likely that the private key is saved in *.ppk format. If this is the case, you will need to convert it to OpenSSH format.
Converting in Windows¶
After opening PuTTYgen, go to Conversions ‣ Import Key, locate and select your private key in *.ppk format.
Now that the key is loaded, go to Conversions ‣ Export OpenSSH key, and choose a name and destination (if you only use one key, we recommend naming it “id_rsa”)
Converting in Linux (Ubuntu)¶
First you will need to install the following package, which provides tools for conversion:
Assuming your private_key.ppk is located in your home’s root (~/private_key.ppk) and we want to save it as id_rsa in .ssh directory:
Make sure the permissions are ok for the private key file:
Converting in Mac OS X¶
Installing PuTTY in Mac OS X, makes use of external tools, thus we recommend either converting in Linux or Windows as aforementioned.
General Policies¶
- Entry node can only be used to: compile code, prepare parameter files, submit runs.
- Do not submit runs with unknown behaviour (under development/testing). Any misbehaving program can and will be instantly killed without warning.
- Account sharing in Lobo is strictly forbidden.
- Abuse regarding any of these rules may get your account suspended for any amount of time.
Support Request¶
If you run into any problem, reach out to us through the email imm-itsupport@medicina.ulisboa.pt and choose the category accordingly. Help us helping you, by providing a clear description of your problem, with the error or log file, if applicable.
There is also a slack channel for all users of this cluster to exchange ideas and experiences. To join, simply login in immlisboa-lobo.slack.com, with your @medicina.ulisboa.pt email account and start participating.
System Overview¶
- 2 Storage Servers/Login Nodes
- 2x Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz (8 Cores each, 16 Total)
- 24GB Ram
- 15 Computational Servers
- 9 Higher Memory Machines (Nodes 2-4, 10-12 and 18-20)
- 18x Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz (10 Cores/20 Threads each)
- 254 GB Ram
- 6 Lower Memory Machines (Nodes 1,5, 9, 13, 17 and 21)
- 12x Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz (10 Cores/20 Threads each)
- 126GB RAM
- Total Resources Available
- 300 Cores/600 Threads of Processing Power
- 3 TB RAM
- Scratch Area 18 TB SSD Distributed Storage RAID 1 Redundant
- 150 TB HDD Storage RAID 6 Redundant